Executive Summary
Cloud computing has become the operational backbone of modern enterprises. From powering customer-facing applications to enabling internal workflows, analytics, and automation, cloud platforms now support nearly every critical business function. Yet despite massive investments in cloud adoption, many organizations continue to struggle with inconsistent performance, unexpected downtime, and operational complexity.
This is the paradox of today’s cloud landscape: more cloud, yet more fragility.
A future-ready cloud is no longer optional. Enterprises face increasing pressure to deliver always-on digital experiences, support distributed teams, and scale rapidly—without sacrificing performance, security, or reliability. Traditional cloud strategies that once worked are no longer sufficient in an environment defined by global users, real-time expectations, and constant disruption.
This whitepaper explores:
- Why cloud performance challenges persist despite widespread adoption
- What defines a truly future-ready cloud architecture
- How enterprises can design for seamless performance at scale
- The role of AI, automation, governance, and resilience in modern cloud environments
- How Yoroflow Cloud Services delivers dependable, high-performance cloud operations built for the future
By the end, decision-makers will gain a practical framework for moving from basic cloud adoption to cloud mastery, where performance, resilience, and business outcomes move in lockstep.
“The future of cloud isn’t about who scales the fastest—it’s about who stays reliable when everything else breaks.”
Let's see the glimpse below,
- The Cloud Performance Paradox
- Defining a Future-Ready Cloud Architecture
- Designing for Seamless Performance at Scale
- Multi-Cloud and Hybrid Cloud: Performance Without Compromise
- AI-Driven Cloud Operations (AIOps)
- Security, Compliance, and Performance—Not Trade-Offs
- Cost Optimization Without Performance Degradation
- Building Resilience for the Unexpected
- Cloud Governance for Long-Term Performance
- Roadmap to a Future-Ready Cloud
- Real-World Use Cases: Seamless Performance in Action
- When the Internet Breaks: Lessons from Recent Cloud Outages
- Yoroflow Cloud Services (YoroDrive): Built for Seamless Performance
- Conclusion: From Cloud Adoption to Cloud Mastery
The Cloud Performance Paradox
Cloud adoption continues to accelerate worldwide. According to Gartner, global end-user spending on public cloud services is projected to exceed $675 billion, driven by digital transformation, remote work, and AI-powered applications. Yet performance gaps remain a persistent challenge.
Many organizations discover that after migrating to the cloud:
- Applications experience unpredictable latency
- Outages impact multiple systems at once
- Costs rise without corresponding performance improvements
One of the most common misconceptions is that moving to the cloud automatically improves reliability. In reality, cloud environments amplify both strengths and weaknesses. Poorly designed architectures simply fail at a larger scale.
The Lift-and-Shift Myth
“Lift-and-shift” migrations—moving workloads to the cloud without re-architecting—remain popular because they’re fast. But they often:
- Retain legacy inefficiencies
- Create performance bottlenecks
- Increase dependency on single providers
Why Scalability Doesn’t Always Equal Reliability
Cloud platforms are built to scale, but scale alone doesn’t guarantee resilience. A system can handle millions of users and still fail due to:
- Configuration errors
- Shared infrastructure dependencies
- Network-level disruptions
This paradox highlights the need for intentional, performance-led cloud design.
Defining a Future-Ready Cloud Architecture
A future-ready cloud architecture is designed not just for today’s workloads, but for tomorrow’s uncertainties. It assumes change, failure, and growth—and plans for them.
What Makes a Cloud Environment Truly Future-Proof?
A future-ready cloud must be:
- Adaptable to changing demands
- Resilient against disruptions
- Intelligent in how it monitors and optimizes itself
- Secure without sacrificing speed or usability
Core Pillars of a Future-Ready Cloud
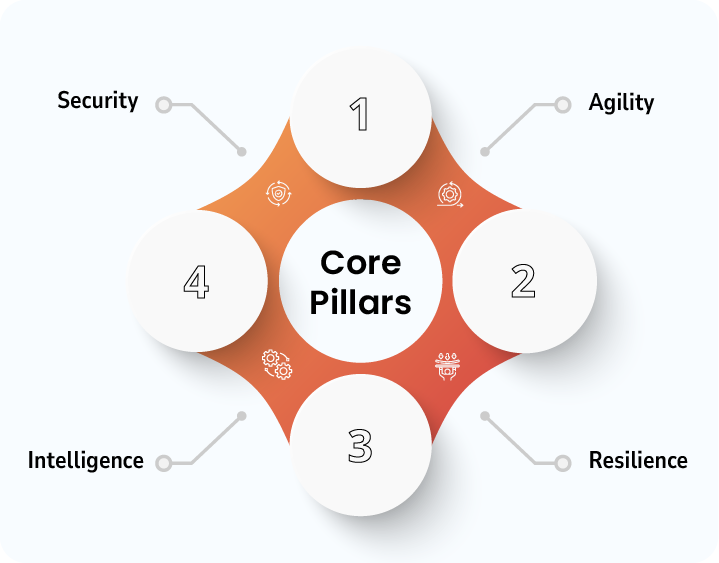
- Agility – Rapid scaling, deployment, and iteration
- Resilience – Built-in redundancy and fault tolerance
- Intelligence – Data-driven optimization and automation
- Security – Embedded, not bolted on
The shift is from reactive infrastructure—where teams respond to issues after they occur—to proactive performance, where systems anticipate and prevent disruptions.
“Resilience is no longer a backup plan. It’s the foundation of modern cloud design.”
Designing for Seamless Performance at Scale
Performance must be treated as a first-class design principle, not an afterthought.
Performance-First vs Cost-First Architecture
While cost optimization matters, prioritizing cost alone can undermine performance. Over-consolidation, aggressive resource trimming, and under-provisioning often lead to:
- Latency spikes
- System instability
- Poor user experiences
A performance-first approach balances efficiency with reliability.
Key Performance Enablers
- Load balancing to distribute traffic intelligently
- Elastic scaling to handle demand surges
- Smart resource allocation based on usage patterns
Reducing Latency in Global Environments
For distributed users, proximity matters. Techniques such as regional deployment, intelligent routing, and optimized data flows help minimize latency and maintain consistent performance worldwide.
Multi-Cloud and Hybrid Cloud: Performance Without Compromise
Enterprises are increasingly adopting multi-cloud and hybrid cloud strategies to reduce dependency on a single provider and build greater operational resilience. According to Flexera’s State of the Cloud Report, over 87% of enterprises now use multiple cloud providers—a clear signal that organizations are prioritizing flexibility, reliability, and performance over convenience.
Why Organizations Move Beyond Single-Cloud
- Risk mitigation: Relying on a single cloud provider exposes organizations to outages, service limitations, and regional disruptions. Multi-cloud strategies distribute risk across environments, ensuring business continuity even when one provider experiences downtime.
- Regulatory requirements: Many industries face data residency and compliance requirements that mandate workloads be hosted in specific regions or environments. Hybrid and multi-cloud models allow organizations to meet regulatory obligations without sacrificing performance.
- Performance optimization: Different cloud providers excel at different workloads. By placing applications where they perform best—closer to users or optimized for specific services—organizations can reduce latency and improve responsiveness.
- Strategic flexibility: Multi-cloud environments prevent vendor lock-in, giving enterprises the freedom to adopt new technologies, negotiate costs, and evolve architectures without being constrained by a single ecosystem.
Performance Challenges
Managing performance across multiple environments introduces complexity. Teams often struggle with fragmented visibility, inconsistent monitoring tools, and data movement latency between clouds—issues that can undermine performance if not addressed.
- Fragmented visibility: Performance insights are scattered across platforms, making it harder to detect issues early.
- Inconsistent tooling: Different cloud-native tools increase operational complexity and slow response times.
- Data movement latency: Transferring data between clouds can introduce delays that impact real-time applications.
Best Practices
- Unified monitoring and orchestration: Centralized visibility ensures consistent performance management across environments.
- Standardized architectures: Common design patterns reduce complexity and improve reliability.
- Centralized performance dashboards: Real-time metrics help teams quickly identify and resolve performance bottlenecks.
Done right, multi-cloud doesn’t dilute performance—it strengthens it.
AI-Driven Cloud Operations (AIOps)
Manual cloud management can’t keep up with modern complexity. This is where AIOps come in.
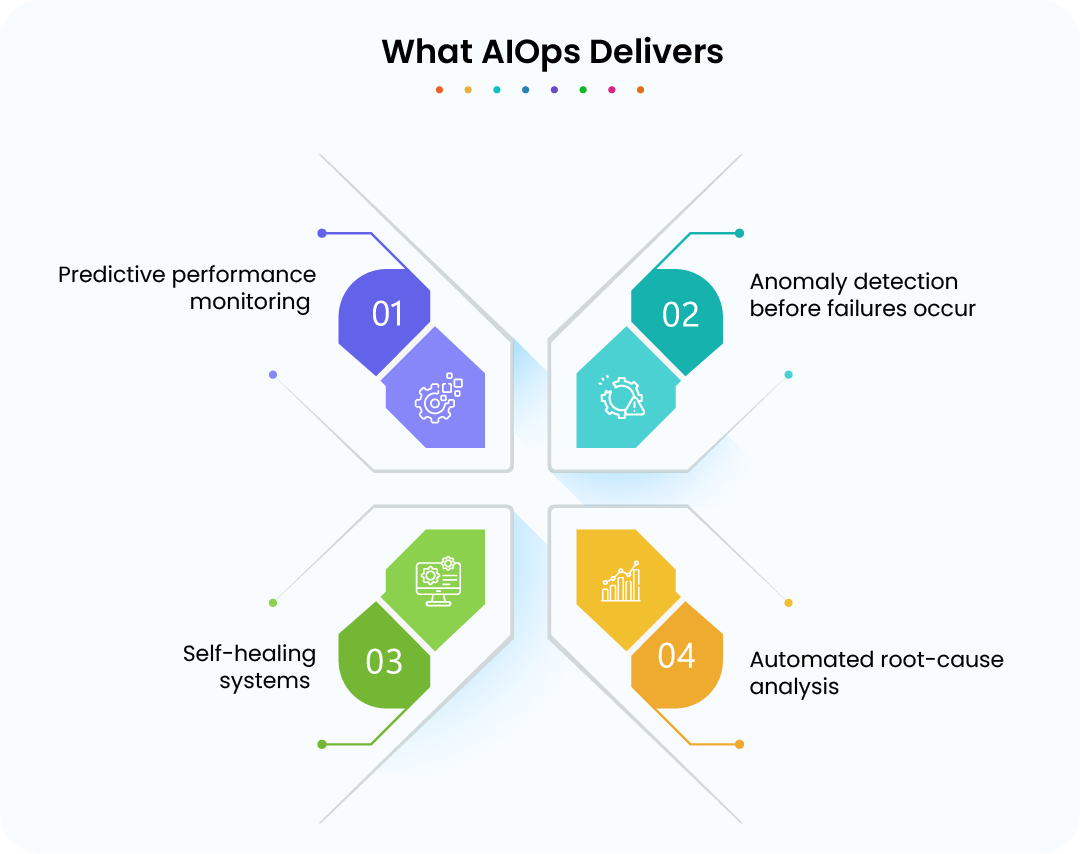
What AIOps Delivers
- Predictive performance monitoring: Uses historical data and real-time system metrics to anticipate performance issues before they impact users, enabling proactive capacity planning and issue prevention.
- Anomaly detection before failures occur: Continuously learns normal system behavior and identifies unusual patterns early, helping teams detect potential disruptions without relying on static thresholds.
- Automated root-cause analysis: Correlates logs, metrics, and events across systems to quickly identify the underlying cause of incidents, reducing investigation time and accelerating resolution.
- Self-healing systems: Automatically resolve common performance issues by scaling resources, rerouting traffic, or restarting services, ensuring continuity and minimizing downtime without manual intervention.
According to IDC, organizations using AI-driven operations reduce downtime by up to 45% and operational costs by 30%.
From Manual to Autonomous
AI transforms cloud operations from reactive firefighting to continuous optimization—freeing teams to focus on innovation instead of incident response.
“In the future-ready cloud, systems don’t wait for humans to fix problems—they fix themselves.”
Security, Compliance, and Performance—Not Trade-Offs
Security is often perceived as a drag on performance. In reality, poorly integrated security is the real bottleneck.
Security as a Performance Enabler
Modern security architectures:
- Reduce attack surfaces
- Prevent disruptive incidents
- Enable safer automation
Zero Trust in High-Performance Clouds
Zero Trust ensures every request is verified without slowing operations, when implemented correctly.
Compliance Without Friction
Automated compliance checks and policy-driven controls eliminate manual overhead while maintaining regulatory standards.
Cost Optimization Without Performance Degradation
FinOps has become essential—but over-optimization can hurt performance.
Hidden Costs of Over-Optimization
- Resource contention
- Increased failure rates
- Lower system resilience
Balancing FinOps and Performance Engineering
Smart cost management aligns spending with performance needs rather than arbitrary reduction targets.
Capacity Planning for the Long Term
Predictive analytics help organizations provision just enough capacity—without sacrificing reliability.
Building Resilience for the Unexpected
Outages, traffic spikes, and failures are inevitable. Resilience determines how systems respond.
Key Resilience Strategies
- Real-time failover
- Geographic redundancy
- Fault-tolerant design
The Uptime Institute reports that 80% of organizations have experienced at least one significant outage in recent years—making resilience a business imperative.
Cloud Governance for Long-Term Performance
Without governance, cloud environments drift.
Why Governance Matters
- Prevents cloud sprawl: Establishes clear policies for provisioning, usage, and decommissioning, ensuring resources remain optimized and aligned with performance goals.
- Maintains performance standards: Enforces baseline configurations and service-level expectations, reducing variability across environments and workloads.
- Ensures accountability: Defines ownership and responsibility for cloud resources, making it easier to track performance impacts and corrective actions.
Performance KPIs
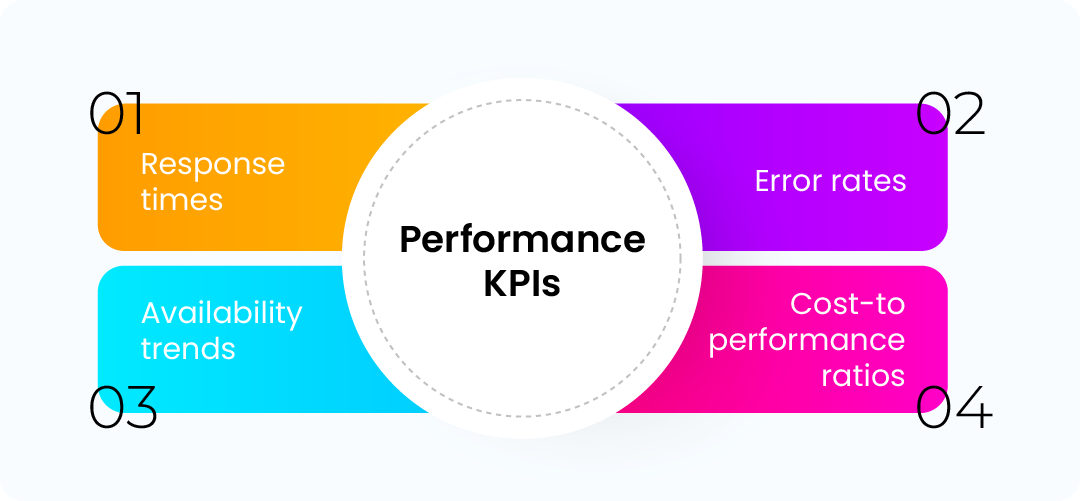
Modern governance tracks:
- Response times: Measures how quickly applications and services react under real-world load conditions.
- Error rates: Identifies stability and reliability issues before they escalate into user-facing problems.
- Availability trends: Monitors uptime patterns over time to ensure consistent service delivery.
- Cost-to-performance ratios: Evaluates whether spending directly translates into measurable performance value.
Governance turns performance into a measurable, repeatable outcome.
Roadmap to a Future-Ready Cloud
Building a future-ready cloud is not a one-time migration—it’s a continuous transformation. Organizations that achieve long-term performance and resilience follow a structured roadmap that balances technology, operations, and user expectations.
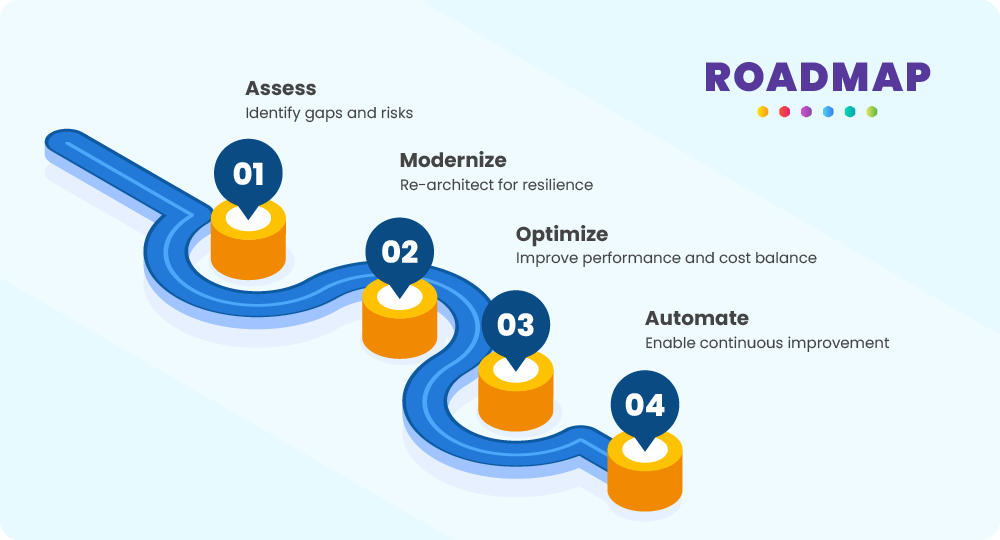
1. Assess – Identify gaps and risks
The journey begins with a comprehensive assessment of the existing cloud environment. This includes evaluating architecture, performance bottlenecks, dependency concentration, security posture, and operational risks. By identifying single points of failure, underutilized resources, and workload inefficiencies early, organizations gain clarity on where change is most urgent and impactful.
2. Modernize – Re-architect for resilience
Modernization focuses on redesigning systems to withstand disruptions. This often involves adopting modular architectures, improving workload isolation, enabling multi-region deployment, and reducing reliance on any single provider or service. The goal is to ensure continuity even during large-scale outages or unexpected demand spikes.
3. Optimize – Improve performance and cost balance
Once modernized, the environment must be continuously tuned. Performance optimization includes improving response times, reducing latency, and ensuring consistent service levels, while cost optimization ensures that every resource delivers measurable value. Right sizing and intelligent resource allocation play a critical role here.
4. Automate – Enable continuous improvement
Automation brings the roadmap to life. From performance monitoring and scaling to remediation and governance, automation enables faster responses, fewer manual errors, and continuous optimization without operational overhead.
Success is measured not just by uptime, but by consistency, adaptability, and user experience.
Real-World Use Cases: Seamless Performance in Action
High-Growth Enterprises
Fast-scaling organizations rely on performance-led cloud strategies to avoid slowdowns during rapid expansion.
Regulated Industries
Healthcare, finance, and government sectors require consistent performance while meeting strict compliance requirements.
Key Lesson
Performance excellence is not industry-specific—it’s architecture-specific.
When the Internet Breaks: Lessons from Recent Cloud Outages
Despite advances in cloud technology, recent events have shown that even the most widely used internet platforms remain vulnerable to large-scale disruptions.
Recently, the internet experienced a significant outage when Cloudflare went down, triggering a ripple effect across multiple major platforms. Services such as X, ChatGPT, Spotify, Canva, and several gaming platforms were impacted. Users reported widespread issues, including error messages, slow loading times, and complete lockouts.
For businesses and teams relying on these platforms, the impact was immediate:
- Workflows stalled
- Collaboration tools became inaccessible
- Customer interactions were delayed
- Productivity dropped across the board
What made this disruption especially notable was that it wasn’t caused by a cyberattack. Instead, it highlighted a deeper issue: shared infrastructure dependencies. When a foundational internet service experiences disruption, the consequences cascade quickly across otherwise unrelated platforms.
This incident was not an isolated case.
Earlier in 2025, AWS and Azure experienced major outages that affected enterprise applications, integrations, and cloud-based services worldwide. Organizations that relied heavily on single-provider ecosystems had limited options but to wait for recovery—often at the cost of business continuity.
These events underscore a critical reality of modern cloud computing:
“Outages are no longer rare exceptions—they are recurring risks built into highly interconnected cloud ecosystems.”
The key differentiator is no longer whether outages occur, but how well platforms are designed to withstand them. Enterprises now require cloud environments that prioritize independence, resilience, and uninterrupted access—especially during unexpected disruptions.
This growing need for performance continuity sets the stage for platforms engineered with resilience at their core.
Yoroflow Cloud Services (YoroDrive): Built for Seamless Performance
Yoroflow Cloud Services, powered by YoroDrive, is designed with future-ready cloud principles at its core—delivering performance, resilience, and control without compromise. YoroDrive serves as the secure cloud foundation within the YoroFlow ecosystem, enabling teams to store, manage, and access critical business data while maintaining uninterrupted performance across workflows.
Unlike traditional cloud platforms that prioritize scale over stability, YoroDrive is engineered with a performance-first architecture that ensures consistent access—even during large-scale internet disruptions.
What Sets Yoroflow and YoroDrive Apart
Performance-First Architecture
YoroDrive is built to support high-performance workloads without latency spikes or availability trade-offs. Its architecture prioritizes responsiveness, ensuring users experience smooth access to files, workflows, and automation regardless of scale or demand.
Built-In Resilience and Independence
YoroDrive is designed to minimize dependency concentration, reducing exposure to single-provider failures. This architectural independence allows Yoroflow Cloud Services to maintain uptime even when widely used internet infrastructure or hyperscale providers experience outages.
Intelligent Automation Across Workflows
Integrated deeply into the Yoroflow platform, YoroDrive works seamlessly with automated workflows—ensuring documents, data, and approvals move forward without manual intervention or performance bottlenecks.
Consistent Uptime During Internet-Level Disruptions
While major platforms experienced outages during events such as Cloudflare disruptions and earlier AWS and Azure incidents, Yoroflow and YoroDrive remained fully operational. Users continued to access files, execute workflows, and collaborate without interruption—maintaining business continuity when it mattered most.
Secure, Role-Based Access Without Performance Overhead
Security and control are embedded directly into YoroDrive through role-based access management, designed to protect data without slowing teams down.
YoroDrive supports clearly defined access levels, including:
- Owner access for full administrative control
- Edit access for users who need to actively collaborate and update content
- View-only access for stakeholders who require visibility without modification rights
This granular access control ensures the right people have the right level of access—no more, no less—while maintaining high performance and eliminating unnecessary friction.
Reliability by Design, Not by Chance
- Yoroflow’s uninterrupted performance is not accidental. It is the outcome of:
- Thoughtful, future-ready architectural design
- Proactive monitoring and performance optimization
- Reduced reliance on single points of failure
- A relentless focus on uptime, trust, and operational continuity
With YoroDrive at its core, Yoroflow Cloud Services delivers more than storage or infrastructure—it delivers confidence. Confidence that your data is accessible, your workflows keep moving, and your business stays productive—even when the internet doesn’t.
Conclusion: From Cloud Adoption to Cloud Mastery
The future-ready cloud is no longer defined by adoption alone—it is defined by how consistently it performs under real-world pressure. As enterprises scale, diversify workloads, and operate across distributed environments, cloud success depends on resilience, intelligent operations, governance, and the ability to deliver seamless performance even during disruption.
Organizations that prioritize performance-first architecture, proactive monitoring, automation, and strong governance are better positioned to adapt to change, absorb unexpected failures, and maintain business continuity. In this landscape, uptime becomes a baseline expectation, while consistency, adaptability, and user experience emerge as true differentiators.
This is where platforms like Yoroflow’s YoroDrive fit into a future-ready strategy. Designed with resilience and independence at its core, YoroDrive supports secure, role-based access (owner, viewing, and editing) while enabling uninterrupted collaboration and workflow continuity. Notably, during periods when major cloud providers and internet platforms experienced widespread outages, Yoroflow remained operational—delivering uninterrupted access and stable performance.
Rather than reacting to failures, YoroDrive demonstrates what modern cloud design should achieve: built-in reliability, intelligent automation, and trust by design. For enterprises preparing their cloud environments for the next decade, solutions that combine performance, resilience, and operational confidence will define the path from cloud adoption to cloud mastery.